Attention Mechanism in Encoder - Decoder Architecture
Dive into the limitations of traditional Seq2Seq models and how attention mechanisms revolutionized neural machine translation.

In traditional sequence-to-sequence (seq2seq) models, neural machine translation relies on an Encoder-Decoder architecture. The Encoder compresses the entire source sentence into a single fixed-length context vector, which is then used by the Decoder to generate the translated sequence. While effective, this approach struggles with long sentences, as condensing the entire input into a single vector can lead to information loss. To address this limitation, Bahdanau, Cho, and Bengio introduced the attention mechanism in their landmark paper, "Neural Machine Translation by Jointly Learning to Align and Translate."
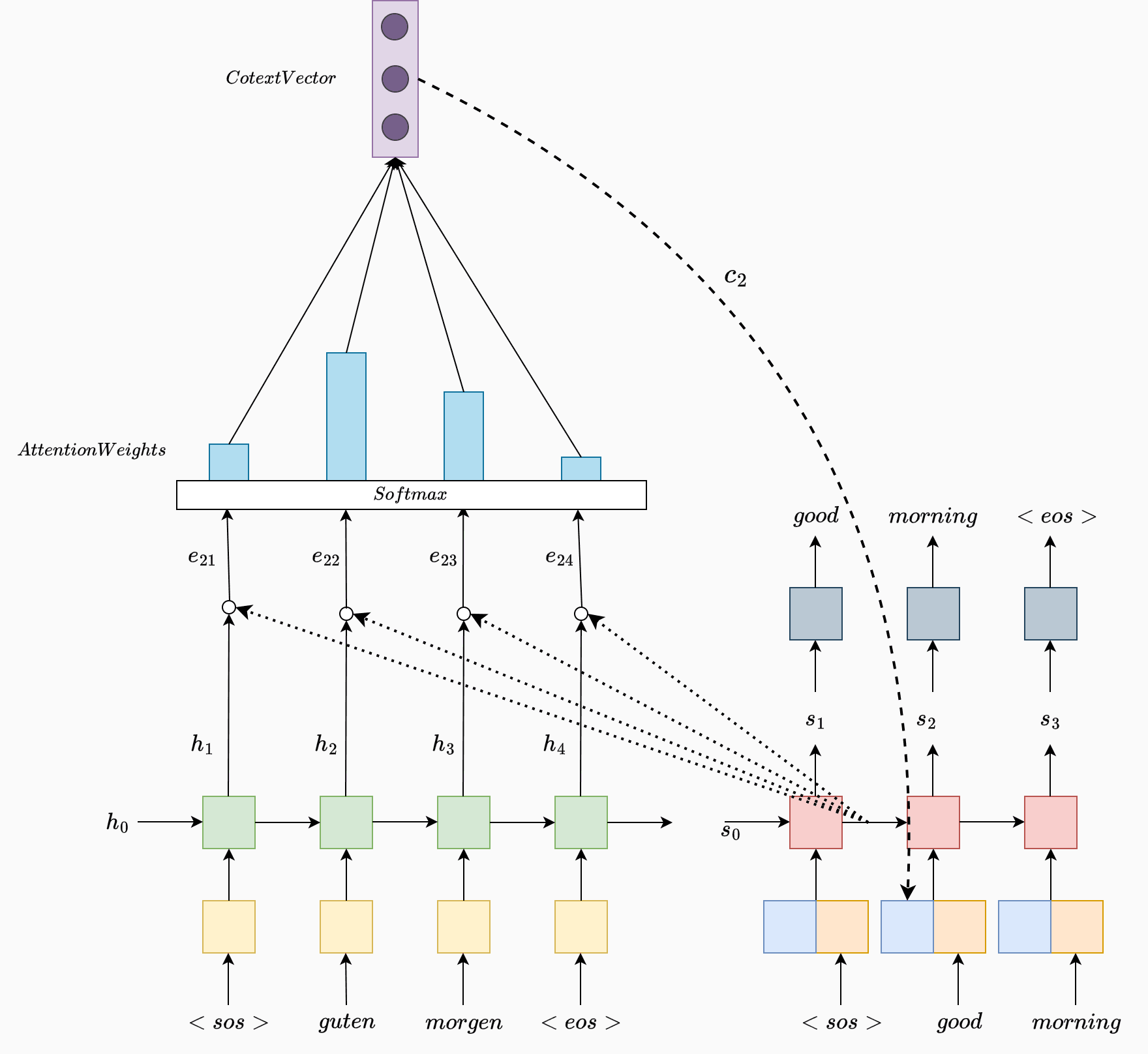
The key idea behind attention is to allow the Decoder to "focus" on different parts of the source sentence for each output word it generates, rather than relying solely on a single fixed context vector. Instead of just feeding the final hidden state of the Encoder to the Decoder, the model calculates a weighted combination of all Encoder hidden states for each target word. This weighted combination is what we call the context vector, but now it dynamically changes with each step of the decoding process.
How Attention Works
-
Encoder Representations: The Encoder processes each word in the source sentence (e.g., "guten morgen") and generates a sequence of hidden states, , where each represents the encoded information of the -th word in the source sentence.
class Encoder(nn.Module): def __init__(self, input_dim, embedding_dim, hidden_dim, n_layers, dropout): super().__init__() # Embedding layer for the input sequence self.embedding = nn.Embedding(input_dim, embedding_dim) # LSTM layer with specified number of layers, hidden dimension, and dropout self.rnn = nn.LSTM(embedding_dim, hidden_dim, n_layers, dropout=dropout, bidirectional=True) # Dropout layer for regularization self.dropout = nn.Dropout(dropout) # Linear layers to compress bidirectional outputs to match the hidden dimension self.fc_hidden = nn.Linear(hidden_dim * 2, hidden_dim) self.fc_cell = nn.Linear(hidden_dim * 2, hidden_dim) def forward(self, src): # shapes are mentioned in coments without batch size for simplicity # src shape: [src_len] # Apply dropout to the embeddings embedded = self.dropout(self.embedding(src)) # embedded shape: [src_len, embedding_dim] # Pass through the bidirectional LSTM encoder_states, (hidden, cell) = self.rnn(embedded) # outputs shape: [src_len, hidden_dim * 2] (mulipliying by 2 because of bidirectional output) # hidden, cell shape: [n_layers * 2, hidden_dim] (2 directions for each layer) # Concatenate the last forward and backward hidden states for each layer hidden = torch.cat((hidden[0:1], hidden[1:2]), dim=2) cell = torch.cat((cell[0:1], cell[1:2]), dim=2) # hidden, cell shape after concatenation: [hidden_dim * 2] # Compress the concatenated bidirectional hidden and cell states hidden = self.fc_hidden(hidden) cell = self.fc_cell(cell) # hidden, cell shape after linear layer: [1, hidden_dim] return encoder_states, hidden, cell -
Alignment Scores: When generating each word in the target sequence, the model computes an alignment score for each source hidden state with respect to the previous Decoder hidden state . This alignment score determines the relevance of each source word to the current target word being generated and is computed as:
Here, is an alignment model that scores how well the source word at position aligns with the target word at position . This alignment model is typically a small neural network trained jointly with the overall translation model.
-
Attention Weights: The alignment scores are then normalized using a softmax function to obtain attention weights . These weights represent the importance of each source word for predicting the current target word and are calculated as follows:
where is the length of the source sentence. The attention weights sum to 1, providing a probability distribution over the source words for each target word.
class Attention(nn.Module): def __init__(self, hidden_dim): super().__init__() self.attn = nn.Linear(hidden_dim * 3, hidden_dim) self.v = nn.Linear(hidden_dim, 1, bias=False) def forward(self, hidden, encoder_states): # hidden shape: [1, hidden_dim] # encoder_states shape: [src_len, hidden_dim * 2] src_len = encoder_states.shape[0] # Repeat hidden state src_len times hidden = hidden.repeat(src_len, 1, 1) # hidden shape after repeat: [src_len, hidden_dim] # Concatenate hidden state and encoder states energy = torch.tanh(self.attn(torch.cat((hidden, encoder_states), dim=2))) # energy shape: [src_len, hidden_dim] attention = self.v(energy).squeeze(2) # attention shape: [src_len] return torch.softmax(attention, dim=0) -
Dynamic Context Vector: The context vector for each target word is then computed as a weighted sum of the Encoder hidden states , where the weights are given by
This context vector provides focused information from the source sentence, allowing the Decoder to generate a contextually accurate target word by attending to the most relevant parts of the input.
-
Decoding with Attention: The context vector is combined with the Decoder's hidden state to generate the next word in the target sequence. This process helps align the source and target words by dynamically attending to relevant sections of the source sentence for each target word.
class Decoder(nn.Module): def __init__(self, output_dim, embedding_dim, hidden_dim, n_layers, dropout): super().__init__() # Embedding layer for the output sequence self.embedding = nn.Embedding(output_dim, embedding_dim) # LSTM layer with specified number of layers and hidden dimension self.rnn = nn.LSTM(hidden_dim * 2 + embedding_dim, hidden_dim, n_layers, dropout=dropout) # Linear layers self.fc_out = nn.Linear(hidden_dim, output_dim) # Dropout layer self.dropout = nn.Dropout(dropout) # Attention mechanism self.attention = Attention(hidden_dim) def forward(self, input, hidden, cell, encoder_states): # input shape: [1] input = input.unsqueeze(0) # input shape after unsqueeze: [1, 1] embedded = self.dropout(self.embedding(input)) # embedded shape: [1, embedding_dim] # Calculate attention weights a = self.attention(hidden, encoder_states) # a shape: [src_len] # Multiply attention weights with encoder states to get context vector a = a.unsqueeze(1) encoder_states = encoder_states.permute(1, 0, 2) context = torch.bmm(a, encoder_states).permute(1, 0, 2) # context shape: [1, hidden_dim * 2] # Concatenate context vector and embedding, then pass through RNN rnn_input = torch.cat((embedded, context), dim=2) # rnn_input shape: [1, embedding_dim + hidden_dim * 2] predictions, (hidden, cell) = self.rnn(rnn_input, (hidden, cell)) # output shape: [1, hidden_dim] # hidden, cell shape: [n_layers, hidden_dim] # Concatenate output, context, and embedding for the final prediction #output = torch.cat((output, context, embedded), dim=2) # output shape after concatenation: [1, hidden_dim * 3 + embedding_dim] prediction = self.fc_out(predictions) # prediction shape: [output_dim] --> target vocab size return prediction, hidden, cell
Final Seq2Seq model
The Seq2Seq class combines the Encoder and Decoder into a single cohesive model for sequence-to-sequence tasks. Inside this block, the source sequence is encoded into context-aware hidden states by the Encoder. These states are then dynamically attended to by the Attention mechanism, allowing the Decoder to focus on relevant parts of the source sequence as it generates each target word. The Seq2Seq model also incorporates teacher forcing, where it can conditionally use actual target tokens during training to improve performance. This integrated approach enables the model to handle complex translations and long dependencies effectively.
class Seq2Seq(nn.Module):
def __init__(self, input_dim, output_dim, embedding_dim, hidden_dim, n_layers, dropout, device):
super().__init__()
self.device = device
# Initialize the Encoder, and Decoder within the Seq2Seq model
self.encoder = Encoder(input_dim, embedding_dim, hidden_dim, n_layers, dropout)
self.decoder = Decoder(output_dim, embedding_dim, hidden_dim, n_layers, dropout)
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src shape: [src_len]
# trg shape: [trg_len]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.fc_out.out_features
# Initialize tensor to hold the decoder outputs
outputs = torch.zeros(trg_len, trg_vocab_size).to(self.device)
# Encode the source sequence
encoder_states, hidden, cell = self.encoder(src)
# encoder_states shape: [src_len, hidden_dim * 2]
# hidden, cell shape: [1, hidden_dim]
# First input to the Decoder is the <sos> token
input = trg[0]
# input shape: [1] (single token representing <sos> at start of decoding)
# Decode the target sequence
for t in range(1, trg_len):
# Forward pass through the decoder with attention
prediction, hidden, cell = self.decoder(input, hidden, cell, encoder_states)
# prediction shape: [output_dim]
# hidden, cell shape: [1, hidden_dim]
# Store prediction
outputs[t] = prediction
# Determine if we use teacher forcing
teacher_force = torch.rand(1).item() < teacher_forcing_ratio
top1 = prediction.argmax(0) # Index of the highest probability in the prediction
# top1 shape: [1] (predicted token)
# Choose next input for decoder
input = trg[t] if teacher_force else top1
return outputs
Conclusion
The introduction of the attention mechanism revolutionized neural machine translation by enabling Seq2Seq models to dynamically focus on the most relevant parts of the input when generating each output word, addressing limitations with long sequences. By combining attention with Encoder-Decoder architectures, Seq2Seq models achieve state-of-the-art performance, paving the way for advancements in translation and broader NLP applications like text summarization and question answering.