RAG: Enhancing Language Models with External knowledge
Learn how Retrieval-Augmented Generation (RAG) enhances language models by integrating external knowledge for accurate, context-aware, and up-to-date responses.", image: CoverImage.

Introduction
Retrieval-Augmented Generation (RAG) is a method of combining information retrieval with neural text generation to produce more accurate, contextually relevant, and up-to-date responses. This approach enhances large language models (LLMs) by grounding their outputs in explicitly retrieved documents or knowledge, mitigating common issues such as hallucinations, outdated information, or reliance on memorized facts. Below is a detailed exploration of RAG, its historical background, the problems it solves, its internal components and algorithmic underpinnings, and some of its core applications.
The Evolution of Neural Language Models: From Limitations to Retrieval-Augmented Generation (RAG)
- Early Neural Models and Limitations
- In early neural language modeling, systems relied exclusively on parameters learned during training. This led to issues when the underlying training corpus became outdated or when the knowledge was too vast to be encoded purely in model weights.
- Question Answering (QA) and other knowledge-intensive tasks often required external factual sources. Before deep learning became pervasive, classic information retrieval (IR) systems (like TF-IDF or BM25) provided relevant documents for QA systems to parse. Neural models brought new capabilities (such as better understanding of context and language generation) but still struggled with real-time retrieval of new or detailed knowledge.
- Emergence of Hybrid Systems
- As large language models grew, practitioners began to experiment with “hybrid” techniques—combining IR techniques with neural models. These experiments showed promise because, even if the model was not trained on every possible fact, it could consult external documents at inference time.
- Introduction of RAG
- In 2020, Facebook AI Research (FAIR) introduced a formal framework called “Retrieval-Augmented Generation” (RAG). This framework presented a way to systematically fuse retrieval from a large collection of documents with generation by a neural model. The result was a model that:
- Retrieves relevant documents from a knowledge source (e.g., Wikipedia, domain-specific text corpora).
- Generates an answer or response by conditioning on the query and the retrieved documents.
- In 2020, Facebook AI Research (FAIR) introduced a formal framework called “Retrieval-Augmented Generation” (RAG). This framework presented a way to systematically fuse retrieval from a large collection of documents with generation by a neural model. The result was a model that:
RAG can be viewed as a crucial milestone in the broader effort to build systems that leverage explicit, external knowledge when generating text.
Addressing Knowledge Gaps, Efficiency, and Scalability
- Addressing Knowledge Limitations
- Static Knowledge Problem: Large language models are often trained once, and storing all knowledge within the model’s parameters can be infeasible or quickly outdated.
- Hallucination: When a model doesn’t have certain knowledge or isn’t confident, it can “hallucinate” facts—i.e., produce text that sounds plausible but is incorrect.
- Dynamic Updates
- Evolving Domains: For tasks such as news question answering or real-time customer support, the knowledge changes continuously. A retrieval mechanism that references an external knowledge base (KB) can adapt to new or updated information.
- Efficiency and Scalability
- Parameter Efficiency: Instead of continuously retraining a giant model to absorb new facts, RAG-like systems retrieve relevant information from a large external store. This can reduce the computational and storage burden, because new documents can be added to the knowledge store without retraining the generator model.
- Conditional Computation: Retrieval is often performed only on relevant subsets of the knowledge base, making generation conditioned on a relatively small “window” of knowledge.
Overall, RAG provides a streamlined approach to solving tasks where up-to-date, factual correctness is paramount and entire domains of knowledge might be too large (or too rapidly changing) to embed purely in the model’s parameters.
RAG Architecture and Components
High-Level Overview
A RAG pipeline typically has two main components:
- Retriever: Finds relevant text passages (or documents) from a large corpus based on the user query (or input).
- Generator: Conditions on both the user query and the retrieved text to generate an answer (or response).
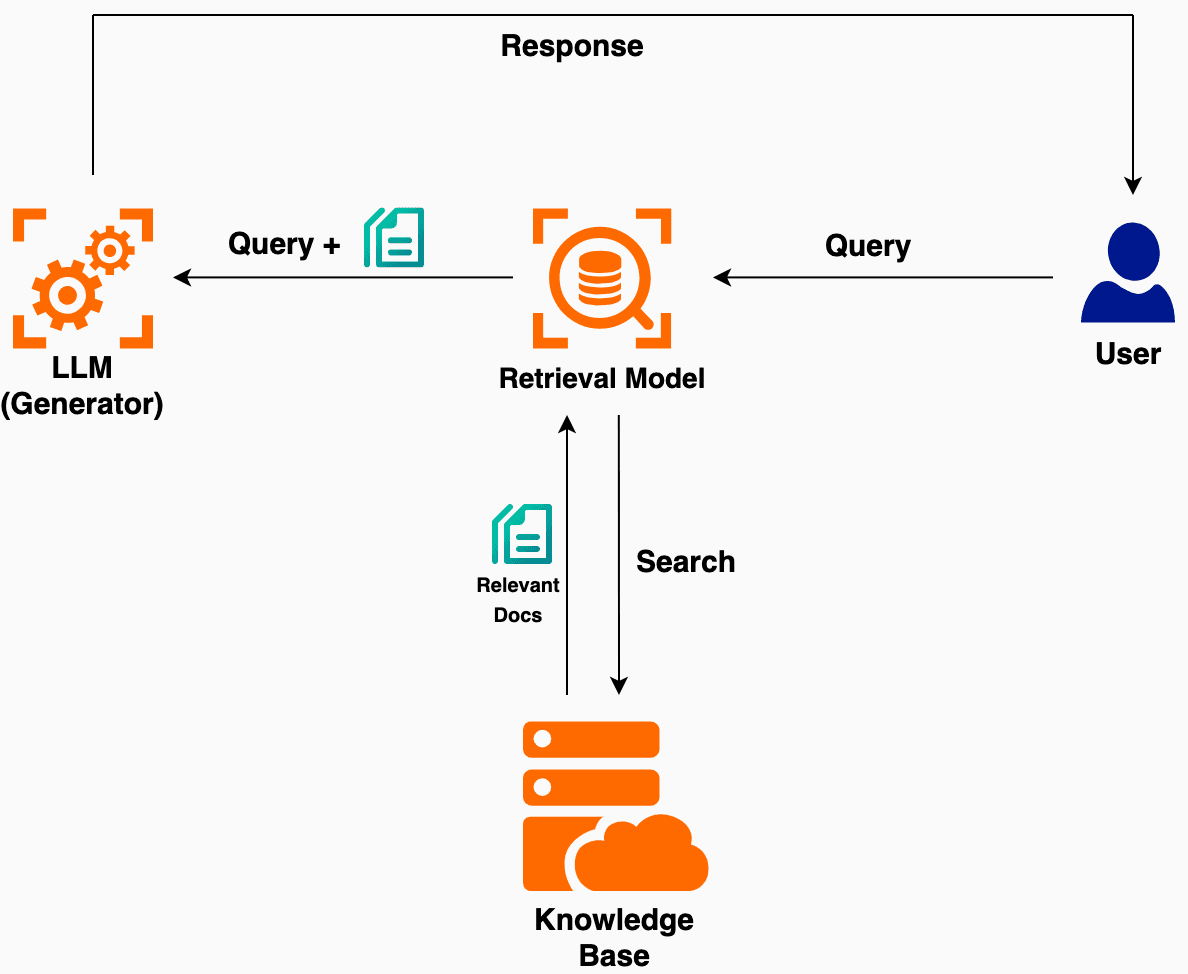
- Retriever:
- Commonly uses dense vector representations (e.g., via a Transformer encoder like BERT, RoBERTa, or a specialized model like DPR—Dense Passage Retrieval).
- Represents both the query and all documents in a vector space.
- Finds the top-k most similar documents/passages to the query.
- Generator:
- Often a Seq2Seq model (e.g., BART, T5) that takes the query and the retrieved text as input and produces a single textual output.
- The architecture merges the original query with each retrieved passage to form a context.
Retriever in Detail
- Index Creation:
- Each document (or passage) from the knowledge base is encoded into a dense vector.
- These vectors are stored in an efficient index, often an approximate nearest neighbor (ANN) index (e.g., FAISS, Annoy, or ScaNN).
- Query Encoding:
- For a given query (or user input), the query encoder produces a dense representation in the same vector space.
- Similarity Search:
- The system computes similarity scores between the query vector and all document vectors, typically using dot product or cosine similarity.
- Returns the top-k relevant documents or passages.
Example Implementation in LangChain
Below is a sample Python snippet using the LangChain library (and some community extensions) to demonstrate how to set up a retrieval-based pipeline, which is the backbone of a RAG system:
# ----------------------------------------------------------
# 1. Load Web Data (e.g., a Wikipedia page on Google)
# ----------------------------------------------------------
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://en.wikipedia.org/wiki/Google")
web_data = loader.load()
# ----------------------------------------------------------
# 2. Split Documents into Manageable Chunks
# ----------------------------------------------------------
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=600,
chunk_overlap=60,
length_function=len
)
documents = text_splitter.split_documents(web_data)
# ----------------------------------------------------------
# 3. Embed the Documents
# ----------------------------------------------------------
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(model="text-embedding-3-large")
# ----------------------------------------------------------
# 4. Create a FAISS Vector Store
# ----------------------------------------------------------
from langchain_community.vectorstores import FAISS
faiss_vctor_store = FAISS.from_documents(documents, embeddings_model)
print(faiss_vctor_store.index.ntotal)
# ----------------------------------------------------------
# 5. Create a Retriever to Fetch Top-k Relevant Chunks
# ----------------------------------------------------------
faiss_vctor_store_retriver = faiss_vctor_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 3}
)
# ----------------------------------------------------------
# 6. Test the Retriever
# ----------------------------------------------------------
retrived_documents = faiss_vctor_store_retriver.invoke("Who founded Google?")
for document in retrived_documents:
print(document.page_content)
print()
# Output:
# Google began in January 1996 as a research project by Larry Page and Sergey Bri# n while they were both PhD students at Stanford University in California.[23][2# 4][25] The project initially involved an unofficial "third founder", Scott Hass# an, the original lead programmer who wrote much of the code for the original Go# ogle Search engine, but he left before Google was officially founded as a compa# ny;[26][27] Hassan went on to pursue a career in robotics and founded the compa# ny Willow Garage in 2006.[28][29]Then Chairman and CEO Eric Schmidt (left) with # co-founders Sergey Brin (center) and Larry
# Google was founded on September 4, 1998, by American computer scientists Larry # Page and Sergey Brin while they were PhD students at Stanford University in Cal# ifornia. Together, they own about 14% of its publicly listed shares and control # 56% of its stockholder voting power through super-voting stock. The company wen# t public via an initial public offering (IPO) in 2004. In 2015, Google was reor# ganized as a wholly owned subsidiary of Alphabet Inc. Google is Alphabet's larg# est subsidiary and is a holding company for Alphabet's internet properties and # interests. Sundar Pichai was appointed CEO of
# (left) with co-founders Sergey Brin (center) and Larry Page (right) in 2008
Generator in Detail
- Context Construction:
- The top-k retrieved passages
{p1, p2, …, pk}are concatenated (or individually fed) along with the queryq. - Different strategies exist, e.g., simply concatenating them into one block of text or prompting the generator k times and then merging the outputs.
- The top-k retrieved passages
- Neural Sequence-to-Sequence Model:
- A transformer-based encoder-decoder (like BART or T5) takes the concatenated query and passages as input.
- The encoder creates hidden states capturing the context.
- The decoder then generates the final response token by token.
- Result:
- The system outputs the final text, which ideally integrates relevant facts from the retrieved
Example Implementation in LangChain
Below is a sample Python snippet using the LangChain library (and some community extensions) to demonstrate how to set up a generation-based pipeline:
# ----------------------------------------------------------
# 1. Define a Prompt for the Generator
# ----------------------------------------------------------
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""
<context>
{context}
</context>
Answer users question based on provided context(above).
question: {input}
""")
# ----------------------------------------------------------
# 2. Load the LLM (Generator)
# ----------------------------------------------------------
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
# ----------------------------------------------------------
# 3. Create a Chain that Combines Retrieval + Generation
# ----------------------------------------------------------
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
documents_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(faiss_vctor_store_retriver, documents_chain)
# ----------------------------------------------------------
# 4. Get a Final Answer from the Chain
# ----------------------------------------------------------
response = retrieval_chain.invoke({"input": "Who founded google ?"})
print(response['answer'])
# Output:
# Google was founded by Larry Page and Sergey Brin.
Applications of RAG
Because RAG excels in leveraging large external knowledge sources, it has significant utility in various domains:
- Question Answering (QA)
- A popular application of RAG is open-domain question answering, where the goal is to answer questions by retrieving relevant passages from an external corpus (e.g., Wikipedia, news articles) and then generating a concise, factual answer.
- Customer Support and Chatbots
- Customer support systems often need to reference up-to-date product documentation, policies, or troubleshooting guides. RAG-based chatbots can dynamically retrieve the relevant support articles and produce more accurate, context-aware solutions for customer inquiries.
- Content Summarization
- Summaries of large document sets or multiple sources can be created by first retrieving the most pertinent sections and then generating a coherent summary. This is especially relevant in fields like finance, legal, and academic research.
- Personal Assistants and Search
- Digital assistants can enhance user queries by retrieving personalized or context-relevant documents (such as emails, notes, or domain-specific knowledge bases) before generating a response.
- RAG-based search can allow more nuanced, generative answers, going beyond standard keyword matches.
- Enterprise Knowledge Management
- Companies often have extensive internal knowledge bases, wikis, or document repositories. RAG can provide employees with quick, accurate answers that cite internal documents, policies, or best practices.
- Biomedical and Scientific Research
- In specialized domains with rapidly evolving information (e.g., medical research, drug discovery, advanced engineering), RAG can retrieve from the latest scientific publications and generate data-driven insights or summaries.
Concluding Thoughts
Retrieval-Augmented Generation (RAG) represents a paradigm shift in the way modern language models handle knowledge-intensive tasks. By integrating retrieval and generation. It addresses the critical challenge of combining the parametric knowledge stored in large language models with non-parametric knowledge stored externally. As LLMs continue to grow in size and complexity, RAG stands out as a robust approach to ensuring factual consistency and up-to-date responses by integrating the advantages of large-scale parametric models with flexible, easily updatable external data repositories.